
Juni 2026 | Kunya
Det finns ett begrepp inom AI som de flesta aldrig har hört talas om. Ändå är det i det tysta den enskilt viktigaste faktorn för om en AI ger dig ett användbart svar eller ett värdelöst. Det kallas för ett kontextfönster — och när du väl förstår det kommer du aldrig att se på AI på samma sätt igen.
Låt oss börja med något du redan känner till.
Din hjärna driver den mest imponerande kontextmotorn som någonsin byggts
Just nu, utan att tänka på det, bär du på en enorm mängd kontext.
Du vet varför du öppnade den här artikeln. Du vet vad du sökte efter innan du hittade den. Du vet vad som hände på jobbet i morse, hur din relation till din chef ser ut, vad du har för mål i år. Du minns ett samtal du hade för tre veckor sedan som i det tysta förändrade hur du ser på ett problem. Du bär med dig dagens känslomässiga kontext. Du vet vad ”den där saken vi pratade om” syftar på utan att någon behöver förklara det.
Allt det där är kontext. Och du håller ihop det utan ansträngning. Din hjärna väver samman årtionden av minnen, preferenser, känslor och bakgrundskunskap i realtid — och använder allt detta för att förstå även den enklaste mening.
När din partner sms:ar ”kan du köpa med det vanliga?” vet du exakt vad det betyder. Det finns ingen data bifogad till det meddelandet. Kontexten finns i ditt huvud.
AI fungerar inte så. Inte än, i alla fall.
Din hjärna driver en kontextmotor som ingen AI har lyckats matcha — och väver samman årtionden av minnen, känslor och kunskap i realtid.
Så vad är ett kontextfönster?
Ett kontextfönster är den mängd information som en AI kan hålla kvar och uppmärksamma vid ett och samma tillfälle.
Varje gång du öppnar en chatt med en AI-modell börjar den om från noll. Den minns inte samtalet ni hade i går. Den vet inte vad du heter om du inte berättar det. Den bär inte på någon bakgrundskunskap om dig, ditt företag eller dina mål. Det enda den ”vet” är det som just nu finns i dess kontextfönster: ditt meddelande, eventuella filer du laddat upp, instruktionerna den fått och konversationshistoriken hittills.
När det fönstret blir fullt börjar saker falla bort. Modellen sammanfattar antingen det som kom tidigare, tappar äldre delar av samtalet eller förlorar helt enkelt greppet om sådant du redan berättat.
Tänk dig att arbeta med en briljant kollega som saknar långtidsminne. Vid varje möte måste du presentera dig igen, förklara projektet från grunden och upprepa den kontext personen behöver. Kollegan är smart. Den kan bara inte minnas.
Tokens: måttenheten för kontext
Kontextfönster mäts i tokens, inte i ord eller tecken.
En token är ungefär 3 till 4 tecken text. Ordet ”kontext” är ungefär två tokens. En hel textsida är cirka 500 till 700 tokens. En genomsnittlig roman ligger runt 100 000 tokens.
Här är en grov guide från verkligheten:
Tokens | Hur det ser ut i praktiken |
|---|---|
4,000 | Några sidor text |
32,000 | En kort novell |
128,000 | En fackbok i full längd |
200,000 | Cirka 500 sidor dokument |
1,000,000 | En hel kodbas, en juridisk akt, 40 000 rader kod |
Det här spelar roll eftersom hela konversationshistoriken räknas mot gränsen när du skickar ett meddelande till en AI. Ditt meddelande, AI:ns tidigare svar, dokument du klistrat in — allt detta använder kontext. När du når gränsen måste något ge vika.

Kontextfönstret är AI:ns arbetsminne — allt den kan se just nu. När det blir fullt börjar tidigare innehåll falla bort.
Varför kontext är allt
Här kommer den ärliga sanningen: kontext är hela spelet.
En AI-modells råa intelligens spelar mindre roll än du tror om den inte har rätt information att arbeta med. Du kan ge världens mest kapabla AI-modell en fråga utan kontext och få ett generiskt, mediokert svar. Eller så kan du ge en något enklare modell full kontext — dina mål, din målgrupp, tonen du vill ha, bakgrunden till situationen — och få något som faktiskt är användbart.
Tänk på skillnaden mellan att be en främling om råd och att fråga en nära vän. Främlingen kanske är smartare. Men vännen känner dig. Den känner till din historia, dina begränsningar och din smak. Rådet landar annorlunda eftersom det är förankrat i kontext.
Det är exakt det som händer med AI. Kvaliteten på resultatet är nästan alltid en funktion av kvaliteten och fullständigheten i den kontext du ger — inte bara av hur kraftfull modellen är.
Det är också därför människor blir frustrerade på AI. De ställer en vag fråga, får ett vagt svar och antar att verktyget inte är särskilt användbart. Det de egentligen upplever är ett kontextproblem.
Kapplöpningen om kontextfönster 2026
AI-branschen vet hur viktigt kontext är. Därför har de senaste två åren präglats av en tyst kapprustning för att göra kontextfönstren så stora som möjligt.
Så här ser läget ut i mitten av 2026:
Modell | Kontextfönster |
|---|---|
Llama 4 Scout | 10,000,000 tokens |
Gemini 3.1 Pro | 2,000,000 tokens |
GPT-5.5 | 1,000,000 tokens |
Claude Opus 4.8 | 1,000,000 tokens |
DeepSeek V4 Pro | 1,000,000 tokens |
Grok 4.3 | 1,000,000 tokens |
Claude Sonnet 4.6 | 1,000,000 tokens |
För att sätta det i perspektiv: 1 miljon tokens räcker för att rymma en hel mjukvarukodbas, en månads kundsupportsamtal eller en komplett juridisk akt — allt i en och samma session.
För bara två år sedan ansågs 128 000 tokens imponerande. I dag är 1 miljon tokens den nya basnivån för frontier-modeller. Gemini 3.1 Pro pressar upp det till 2 miljoner. Llama 4 Scout når 10 miljoner.
Större är dock inte alltid bättre
Här kommer delen som de flesta artiklar hoppar över.
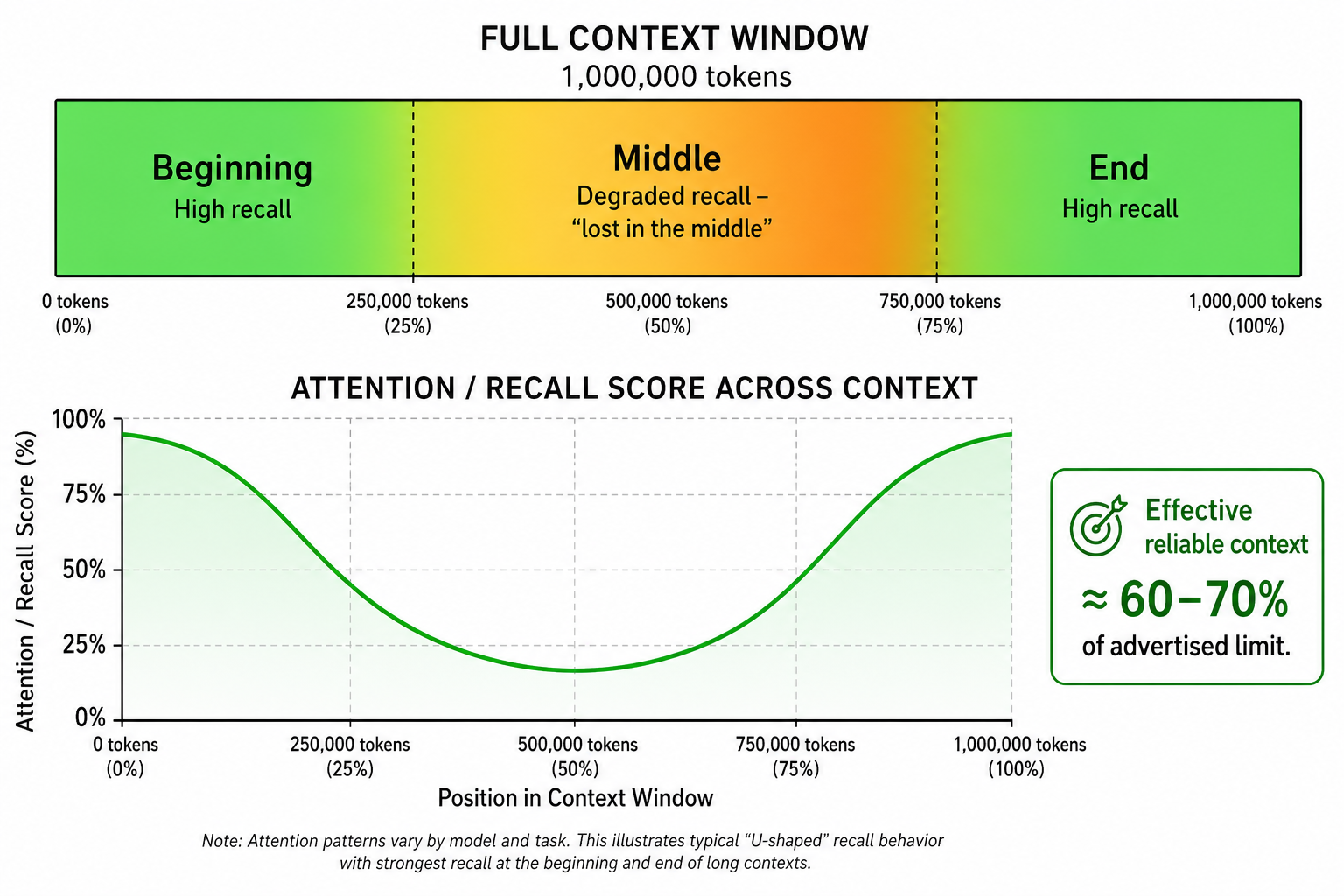
Att ha ett stort kontextfönster betyder inte att en modell använder allt innehåll lika bra. Forskning under 2026 visar konsekvent att AI-modeller tenderar att lägga mer vikt vid information i början och slutet av kontextfönstret — och kan ”tappa bort” sådant som begravs i mitten.
Det här kallas ibland context rot eller problemet ”lost in the middle”. Även de mest avancerade frontier-modellerna visar försämrad återkallning när kritisk information är nedgrävd djupt i en prompt på 1 miljon tokens.
Problemet ”lost in the middle”
Att en modell marknadsför ett fönster på 1M tokens är inte samma sak som att den pålitligt förstår och minns allt genom hela dessa 1M tokens. Den effektivt användbara kontexten ligger ofta närmare 60–70 % av den utlovade gränsen för tillförlitlig prestanda. Därför är det lika viktigt hur du strukturerar din kontext som hur mycket kontext du har.
Skillnaden mellan kontextfönster och minne
Många blandar ihop kontextfönster med minne. Det är inte samma sak.
Ett kontextfönster är aktivt och tillfälligt. Det är det modellen kan se just nu, i den här konversationen. När konversationen avslutas försvinner den kontexten.
Minne, i AI-bemärkelse, är något annat: ett system som lagrar information utanför konversationen och hämtar tillbaka den senare. Vissa AI-produkter börjar bygga funktioner för bestående minne ovanpå sina modeller. Men det underliggande kontextfönstret är fortfarande motorn — minne är bara ett sätt att mata tillbaka användbar information in i det.
Din hjärna gör båda delarna samtidigt utan att du ens märker det. AI försöker fortfarande komma ikapp.
Vad det här betyder för hur du använder AI
Några praktiska slutsatser:
Lägg det viktigaste först. När du inleder en konversation med en AI, ge den kontext direkt. Ditt mål, din målgrupp, dina begränsningar, dina preferenser. Låt den inte gissa. Ju mer kontext du ger i början, desto bättre blir varje svar.
Långa konversationer försämras. Ju längre en chatt pågår, desto mer trängs kontexten undan. Om du arbetar med något komplext kan det vara klokt att starta nya sessioner för olika faser av arbetet i stället för att ha en enda ändlös tråd.
Klistra in det som spelar roll. Om du har ett dokument, en brief eller ett antal instruktioner som är relevanta — klistra in dem. AI kan inte läsa dina tankar. Kontext som den inte kan se är kontext som den inte kan använda.
Större kontextfönster öppnar verkligen nya användningsområden. Med modeller på 1M+ tokens kan du nu låta en AI läsa hela ditt företags dokumentbibliotek innan den svarar på en fråga. Eller analysera en fullständig kodbas. Eller sammanfatta flera månaders kundfeedback på en gång. Det här är inte marginella förbättringar — det är kvalitativt annorlunda kapacitet.
Varför Kunya är byggt kring detta
De flesta AI-plattformar ger dig en modell. Kunya ger dig rätt modell, med rätt kontext, i rätt ögonblick — och den skillnaden betyder allt.
Vi ger dig tillgång till alla frontier-modeller som nämns ovan, i alla kontextnivåer, på ett och samma ställe. Oavsett om du behöver Gemini 3.1 Pro:s kontextfönster på 2 miljoner tokens för att ta in ett massivt dokumentbibliotek, Claude Opus 4.8 för långsiktigt agentiskt arbete eller GPT-5.5 för komplext resonemang med hela kontexten bevarad — kan du växla mellan dem i samma gränssnitt utan att jonglera separata abonnemang, separata inloggningar eller separata fakturor.
Men tillgång till stora kontextfönster är bara halva problemet.
Den andra halvan är att veta vad du faktiskt ska lägga in i dem.
Att hälla in allt du har i ett kontextfönster på 1 miljon tokens är ingen strategi. Det är brus. Problemet ”lost in the middle” som vi beskrev tidigare försvinner inte bara för att du har mer utrymme — det blir värre när kontexten är uppsvälld, ofokuserad eller dåligt strukturerad. Ett kontextfönster fyllt med irrelevant information är aktivt skadligt. Det späder ut signalen. Det får modellen att jaga fel saker.
Därför är Kunya byggt kring intelligent kontexthantering, inte bara åtkomst till stora kontextfönster.
Kunyas agenter och verktyg är utformade för att hitta exakt det som hör hemma i kontextfönstret innan modellen ens får se det. I stället för att ladda in allt och hoppas på det bästa hämtar Kunyas retrieval-verktyg de specifika dokument, textutdrag, konversationshistoriker eller datapunkter som faktiskt är relevanta för din aktuella uppgift. Tänk på det som en researchassistent som läser hela arkivet så att du slipper — och ger dig bara de tre sidor som faktiskt spelar roll.
Intelligent kontexthämtning: i stället för att ladda in allt lyfter Kunyas verktyg fram bara det som faktiskt är relevant — så modellen arbetar med signal, inte brus.
Det gör två saker. För det första förbättrar det dramatiskt kvaliteten på AI:ns svar, eftersom den kontext den får är tät av signal i stället för utspädd av brus. För det andra skyddar det dig från att bränna onödiga tokens på innehåll som aldrig skulle ha hjälpt. Kontextfönster är kraftfulla, men de är inte gratis. Varje token räknas, särskilt i stor skala.
Våra agentiska arbetsflöden tar detta ett steg längre. Kunya-agenter kan dela upp komplexa uppgifter i steg och bara föra relevant kontext vidare i varje steg i stället för att bära hela tyngden av allt genom hela processen. Modellen har alltid det den behöver. Den bär aldrig mer än den borde.
Den här filosofin är också grundläggande för hur vi byggde KunyaV1, vår egen proprietära stora språkmodell. KunyaV1 utformades inte kring rå parameterstorlek eller topplaceringar på benchmarklistor. Den utformades kring kontexteffektivitet — förmågan att få ut maximal förståelse ur ett välstrukturerat och precist avgränsat kontextfönster. Där många modeller tränas för att hantera vad som än kastas på dem, är KunyaV1 tränad för att arbeta med ren, målinriktad kontext och ge tillbaka svar som speglar den precisionen.
Det är ett annat vägval än det mesta av branschen gör. Men vi tror att det är rätt väg. För efter allt som forskningen visar, och efter allt vi har byggt och testat, kommer vi gång på gång fram till samma slutsats: modellen som använder sin kontext klokt kommer att prestera bättre än modellen som bara har mer av den.
Kontext är allt. Kunya är byggt på den övertygelsen.
Testa Kunya gratis
Utforska 100+ modeller i alla kontextnivåer — från 1M till 10M tokens — på en och samma plattform. Inget kreditkort krävs.


